2 EL KERNEL
2.1 żQUÉ ES EL KERNEL?
El kernel es el sistema central de cualquier sistema operativo. Todos los sistemas
operativos constan de una parte encargada de gestionar los diferentes procesos y las
posibles comunicaciones entre el hardware de un ordenador con los programas que están
en funcionamiento, entre otras y variadas tareas. Es, por ejemplo, el que facilita el acceso
a datos en los distintos soportes posibles (CD-ROM, unidad de disco duro, unidad ZIP, etc.), o
el que arranca el ordenador, o el que resetea todos los dispositivos que sean necesarios.
La principal propiedad de un kernel es que todas estas operaciones de manejo de memoria o
de dispositivos, son, desde un punto de vista de usuario, totalmente transparentes, esto
es, no es necesario saber como trabajar a bajo nivel con el procesador para realizar las
operaciones que sean necesarias, ya que será el kernel, a través de una serie de instrucciones
ya implementadas el que lo hará por nosotros.
Para todo aquel que llegado este punto desee continuar con la lectura de este
apartado, quiero advertirle que si está buscando una ayuda rápida de nivel medio-avanzado,
no espere encontrarla en esta web. Aquí únicamente trato las diferentes partes de que consta el
kernel y su funcionamiento, pero no el uso del sistema operativo. Para el que esté interesado
en este tema le recomiendo conseguir el libro [MP98], el cual
es una introducción a este gran sistema operativo para un usuario no iniciado en él.
2.1.1 Estructura del sistema
Los kernels de Windows NT o Minix son de tipo micro-kernel, caracterizado
porque proveen al sistema de un estado mínimo necesario de funcionalidad, cargando el resto
de funciones necesarias en procesos autónomos e independientes unos de otros, comunicándose
con este micro-kernel a través de una interfaz bien definida. Este tipo de estructura es más
fácil de mantener y el desarrollo de nuevos componentes es mucho más simple, dando a su vez una
mayor estabilidad al sistema. Por otro lado, debido a la estructura rígida del interfaz, estos
tipos de kernel son mucho más complicados de reestructurar, y además, debido a las arquitecturas
del hardware actual, el proceso de intercomunicación dentro del micro-kernel es mucho más que una
simple llamada, por lo que hace que esta estructura sea más lenta que los kernels de tipo
monolíticos o macro-kernels.
No hay que olvidar que Linux ha sido desarrollado
como un simple placer por desarrollar un sistema, el cual ha evolucionado gracias a
diferentes programadores de todo el mundo. Debido a esto, una estructura de micro-kernel es
prácticamente inconcebible, aunque esto no quiere decir que el kernel de linux sea
una simple lista de instrucciones sin estructura alguna. A pesar de la estructura de macro-kernel,
se ha intentado equiparar su velocidad utilizando código optimizado en velocidad (aunque complicado
de entender), y se ha recuperado algunas de las mejores características de la estructura de micro-kernel,
como puede ser la carga de los diferentes drivers necesarios como módulos independientes, siempre
sin olvidar la estructura monolítica original.
En el caso de Linux, la gran parte del kernel está escrito en C, existiendo también
instrucciones en ensamblador, aunque estas ultimas se usan mayoritariamente en los procesos de arranque
y en el control de co-procesador. A continuación se muestra una tabla con la cantidad de lineas en C y
ensamblador que se usan aproximadamente en la versión 2.0 del kernel de Linux, el cual consta de unas
470.000 lineas de código (la versión 1.0 constaba "únicamente" de 165.000 lineas):
|
Código C |
Ensamblador |
| Dispositivos de Drivers | 377.000 | 100 |
| Network | 25.000 | |
| VFS | 13.500 | |
| 13 archivos de sistema | 50.000 | |
| Inicio | 4.000 | 2.800 |
| Co-Procesador | | 3.550 |
Tabla 1 - Proporciones de código fuente por
componente
A modo de curiosidad cabe comentar el significado de la serie de números que acompańan
al kernel, tanto compilado como al directorio que contiene las fuentes de éste, que, a pesar de no ser
necesarios, se suelen incluir porque aportan una mayor información. Este conjunto de cifras tienen el
formato X.X.XX y su significado no es más que la versión del kernel a la que corresponde dicho archivo,
aunque no es simplemente así. Como se puede suponer, la variación en una unidad del primer grupo de cifras
significa un cambio muy importante en el kernel, siendo ésta menor conforme el grupo de cifras que varía
está más hacia la derecha. El último grupo de cifras tiene, además del significado anterior como indicador
de versión, un significado ańadido, que es el de que si la cifra es par, esa versión de kernel se considera
como una versión estable, si, en cambio ésta es impar, se considera que la versión del kernel es una
versión en fase beta o de desarrollo.
2.1.2 Procesos y Tareas
Desde el punto de vista de un proceso ejecutándose en Linux, el kernel es un proveedor
de servicios. Cada proceso existe por separado y el espacio de memoria reservado a cada uno de ellos
está protegido para que no pueda ser modificado. Desde este punto de vista, se está llevando a cabo un
sistema multiproceso real (ver Figura 1).
Desde un punto de vista interno, la cosa es distinta. Solo hay un proceso en marcha
en el ordenador que puede acceder a todos los recursos, el sistema operativo. El resto de tareas se
llevarán a cabo como co-rutinas, las cuales, de una forma totalmente independiente, deciden por ellas
mismas a qué tarea y cuándo pasarán el control. Debido a esto, un fallo en la programación del kernel
podría bloquear todo el sistema.
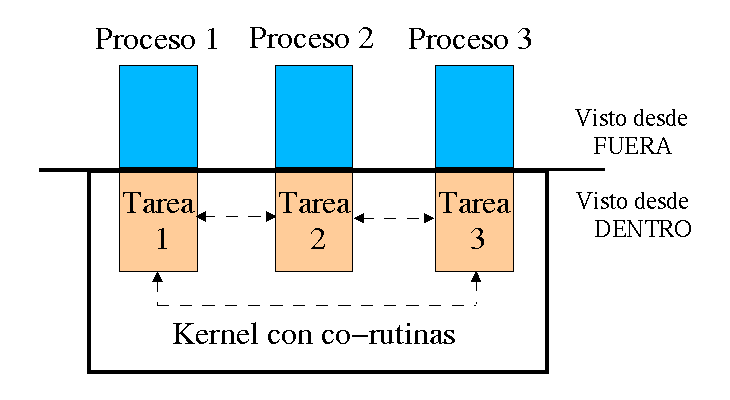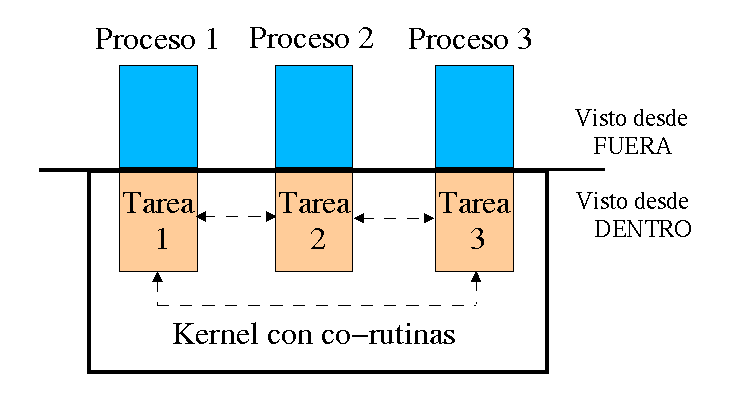
Figura 1 - Los procesos desde una vista interna y externa
Cuando se ha iniciado un proceso, este puede adquirir distintos estados:
- Ejecución (Running)
- La tarea está activa y en ejecución. Este proceso solo puede ser interrumpido por una
interrupción o una llamada del sistema.
- Rutina interrumpida (Interrupt Routine)
- Está rutina se activa con una interrupción del sistema (hardware), como puede ser un pulsación
del teclado o una llamada del reloj.
- Llamada del Sistema (System Call)
- Las llamadas del sistema se activan debido a una interrupción producida por el software.
Pueden suspender una tarea para llevar acabo un evento.
- En espera (Waiting)
- El proceso está en espera de un evento externo.
- Vuelta de la llamada del sistema (Return from system call)
- Este estado se adopta automáticamente después de una llamada del sistema y algunas
interrupciones.
- Preparado (Ready)
- El proceso está en espera de ser atendido por el procesador, que está ocupado con otro
proceso en ese momento.
Estos estados no pueden ser adquiridos sin orden alguno o porque sí, sino que llevan un
ciclo el cual debe ser respetado. Además, como veremos en el siguiente apartado, si observamos la
Figura 3 podremos observar que estos procesos no son "islas" independientes
unas de otras, sino que hay una relación familiar entre ellos.
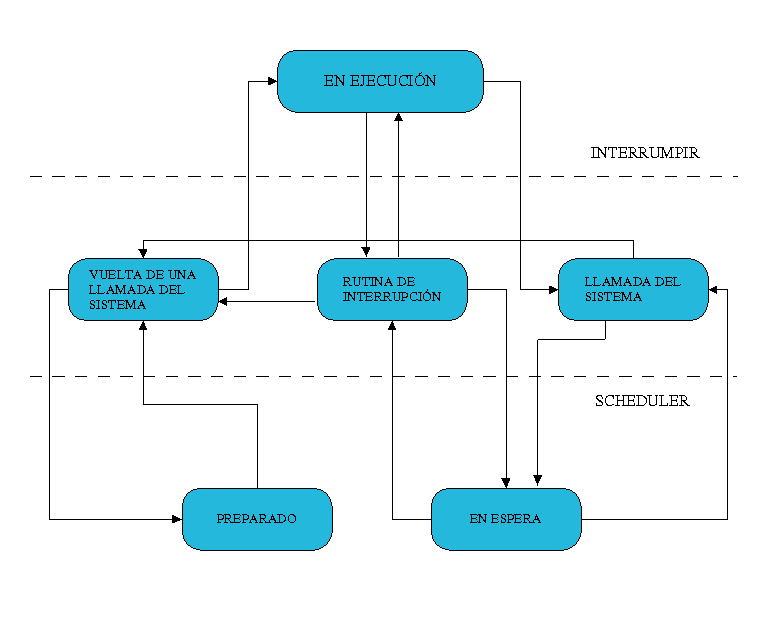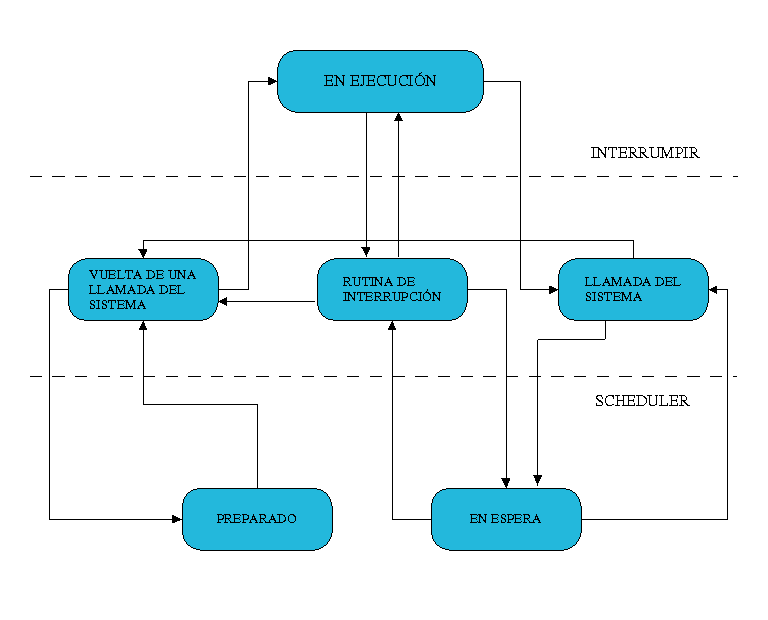
Figura 2 - Estados posibles de un proceso
En muchos sistemas operativos actuales se hace la distinción entre procesos y threads.
Un thread es una especie de rama o camino en la ejecución de un programa que puede ser procesado en
paralelo con otros threads.
Linux no hace esa distinción. En el kernel, únicamente existe el concepto de un proceso,
el cual puede compartir recursos con otros procesos. Por eso, una tarea es una generalización del concepto
de un thread.
2.2 PRINCIPALES ESTRUCTURAS DE DATOS
2.2.1 La estructura Tarea
En un sistema multitarea es muy importante como una tarea está definida. Es,
probablemente, una de los conceptos más importantes en un sistema operativo de este tipo. De hecho los
algoritmos usados en Linux para su manejo constituyen la mayor parte del código del kernel.
La descripción de las características de un proceso, vienen dadas por la estructura
task_struct. Una de las variables usadas es la llamada state, que es la encargada de almacenar el
estado actual de la tarea (los valores que puede tomar esta variable los podemos ver en la
Figura 2). Otras variables son counter, que es la variable usada por el Programador (scheduler) para
seleccionar el siguiente proceso, o signal que contiene un máscara de un bit (bit mask) para las seńales
recibidas por el proceso.
Todos los procesos creados son introducidos en una lista doblemente enlazada gracias
a los dos punteros siguientes (el comienzo y final de esta lista están almacenados en la variable global
init_task):
struct task_struct *next_task;
struct task_struct *previous_task;
|
En un sistema Unix, los procesos no existen independientemente unos de otros, sino que
cada proceso está relacionado con los demás, siguiendo una jerarquía familiar según que proceso lo haya
creado, y que al igual que los anteriores están representados por:
struct task_struct p_opptr; /* Padre original */
struct task_struct p_pptr; /* Padre */
struct task_struct p_cptr; /* Hijo más joven */
STRUCT TASK_STRUCT P_YSPTR; /* YOUNGER SIBLING */
struct task_struct p_osptr; /* OLDER SIBLING */
|
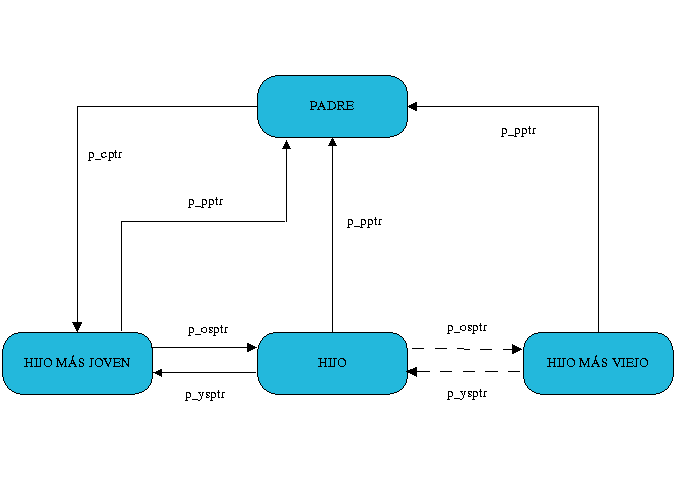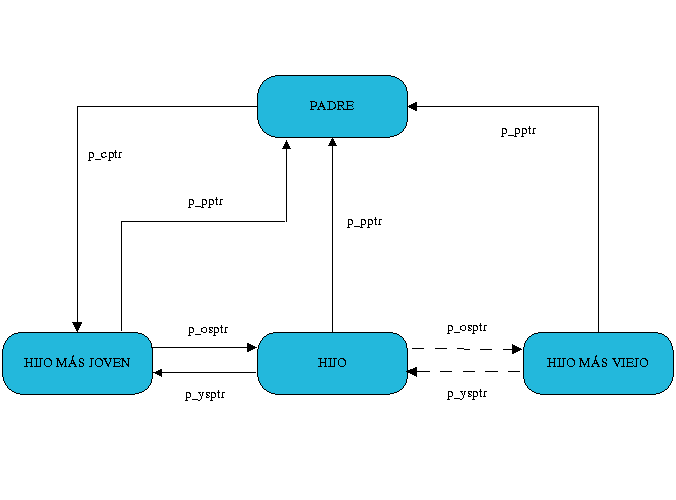
Figura 3 - Relaciones entre procesos
Otras características de esta estructura son, por ejemplo, que cada proceso posee su
propia subestructura para el almacenamiento de datos, o que cada proceso posee un numero identificativo
pid, a partir del cual se nos facilitará el manejo de dicha tarea.
2.2.2 La tabla de procesos
Cada proceso en ejecución que haya en el ordenador, ocupa una entrada en la tabla de
proceso, la cual está restringida aen tamańo a NR_TASKS.
En Linux, la tarea 0 (task[0]) es INIT_TASK, por lo que será la primera tarea cargada por
el kernel. Esto es así por que ella será la encargada de lanzar el resto de tareas, como los demonios
cargados en el inicio (p.ej. lpd) o el controlador del ratón (gpm).
2.2.3 Ficheros e inodes
En los sistemas UNIX se ha hecho tradicionalmente una distinción entre la estructura de
archivos y la de inodes. La estructura inode describe un archivo, aunque esto puede ser visto de
diferentes formas: por ejemplo, la estructura de datos en el kernel y la del disco duro describen
archivos, y, a pesar de ser distintas, se denominan inodes.
Los inodes contienen información del archivo como propietario, derechos, etc. Cada fichero
usado en el sistema se apareja con una única entrada de inode en el kernel, la cual describe
diferentes atributos y propiedades del archivo al que corresponde.
2.3 PRINCIPALES MECANISMOS DEL KERNEL
2.3.1 Seńales
Desde los primeros sistemas UNIX, esta característica ha sido un de las que más ventajas
le han aportado: el uso de seńales. Éstas son usadas por el kernel para informar a los procesos sobre
ciertos eventos, lo que permite abortarlos o cambiarlos de un estado a otro.
Todas estas seńales son enviadas con la función send_sig(), la cual admite el paso de tres
parámetros, siendo éstos: el numero de la seńal, una descripción del proceso que va a recibir la seńal
(o mejor dicho, un puntero a la entrada del proceso en cuestión en la tabla de procesos), y opcionalmente
la prioridad del proceso que envía la seńal. Este último argumento puede tener dos valores: desde el
kernel, el cual puede enviar seńales a cualquier proceso, o desde un proceso, para lo que es necesario
que éste último tenga derechos de superusuario, o bien que tener el mismo UID y GID que el proceso al que
se le envía la seńal.
2.3.2 Tuberías
Las tuberías o pipes (... | ...) son unos enlaces que se pueden realizar con cualquier
shell, que unen las entradas de algunos programas con las salidas de los otros. Gracias a esto es posible
usar gran parte de los comandos de Linux como filtros y, así, construir comandos más potentes a partir de
comandos sencillos. Estas pipes, son consideradas como el método clásico de comunicación entre
procesos.
Otra variante de las tuberías son los FIFOs (First In, First Out), que se diferencian de
las anteriores en que los FIFOs no son objetos temporales, sino que ellos pueden ser establecidos en un
sistema de ficheros.
2.3.3 Interrupciones
Las interrupciones son usadas para permitir al hardware comunicarse con el sistema
operativo. En Linux hay dos tipos de interrupciones: rápidas y lentas. Se podría decir que son tres tipos,
considerando el tercero como las llamadas del sistema, también desencadenadas por interrupciones.
- Interrupciones lentas: Son las más usuales. Se caracterizan porque se puede llevar a cabo otras
interrupciones mientras éstas son tratadas. Después de que una interrupción lenta haya sido procesada,
otras tareas adicionales, de carácter periódico, son llevadas a cabo por el sistema (como por ejemplo
el scheduler). Un ejemplo típico de interrupción lenta es la interrupción del reloj.
- Interrupciones rápidas: Éstas se usan para tareas más cortas y menos complejas que las comentadas
en el apartado anterior. Mientras este tipo de interrupciones son llevadas a cabo, el resto de
interrupciones son bloqueadas, a menos que la propia rutina en ejecución las active. Un ejemplo de este
tipo de rutinas es la interrupción de teclado.
En ambos tipos de interrupciones el proceso que se lleva a cabo es muy similar: primero
todos los registros son salvados con SAVE_ALL y la interrupción envía una confirmación al controlador de
interrupciones con ACK. En caso de un sistema con múltiples procesadores, se ejecuta una llamada a la
rutina del kernel ENTER_KERNEL para sincronizar el acceso al kernel de los procesadores. Una vez se ha
completado la interrupción, se ejecuta la rutina RESTORE_MOST que devuelve los registros guardados
previamente a sus valores iniciales, llamando después a iret para continuar con el proceso
interrumpido.
2.3.4 Iniciando el sistema
LILO es el encargado de encontrar el kernel de Linux y lo carga a la memoria, iniciándolo
en el punto start:, que es donde se encuentra el código en ensamblador encargado de inicializar el
hardware esencial. Una vez esto se ha llevado a cabo, el proceso se cambia a Modo Protegido. La
instrucción en ensamblador
jmp 0x1000, KERNEL_CS
inicia un salto a la dirección de comienzo del código de 32 bit para el kernel del sistema
operativo actual y continua desde startup_32:. En este punto se inician más secciones del hardware (en
particular el MMU, el co-procesador y la tabla de descripciones de interrupciones) y el entorno requerido
para la ejecución de funciones en C. Una vez esto se ha llevado a cabo, la primera función en C,
start_kernel(), es llamada, la cual salvará todos los datos que el código ensamblador ha encontrado sobre
el hardware hasta este punto. Entonces se inicializan todas las áreas del kernel.
asmlinkage void start_kernel(void)
{
memory_start = paging_init(memory_start,memory_end);
trap_init();
init_IRQ();
sched_init();
time_init();
parse_options(command_line);
init_modules();
memory_start = console_init(memory_start,memory_end);
memory_start = pci_init(memory_start,memory_end);
memory_start = kmalloc_init(memory_start,memory_end);
sti();
memory_start = inode_nit(memory_start,memory_end);
memory_start = file_table_init(memory_start,memory_end);
memory_start = name_cache_init(memory_start,memory_end);
mem_init(memory_start,memory_end);
buffer_init();
sock_init();
ipc_init();
...
|
El proceso actualmente en curso es el proceso 0, el cual ejecuta la función init(), que
será la encargada de llevar a cabo el resto de la inicialización, cargando los demonios bdflush y kswap.
Entonces se hace una llamada a setup, que será la encargada de montar el sistema de archivos root.
2.3.5 Interrupción del Reloj
Todos los sistemas operativos necesitan una forma de medir el tiempo y de mantener una
hora en el sistema. El sistema de medida se implementa normalmente haciendo interrupciones en intervalos
ya predefinidos. Bajo Linux, el tiempo se mide en ticks desde que el sistema es arrancado. Un tick
representa 10 milisegundos, así que la interrupción del reloj se efectúa 100 veces por segundo.
El tiempo se almacena en la variable
unsigned long volatile jiffies;
la cual deberá ser modificado únicamente por esta interrupción. Sin embargo, este método
provee solo de un base interna de tiempo.
La interrupción del reloj es llamada relativamente a menudo y, por eso, es un tanto
dependiente del tiempo.
La rutina de interrupción en la versión 2.0, simplemente actualiza la variable jiffies y
marca como activa una parte de la interrupción del reloj, la cual es llamada por el sistema más adelante,
y se desarrolla el resto del trabajo. Como pueden ocurrir varias interrupciones de reloj antes de activar
el resto de rutinas, la interrupción del reloj también puede incrementar las variables
unsigned long lost_ticks;
unsigned long lost_ticks_system;
para que así estas puedan ser evaluadas al final de la rutina.
lost_ticks cuenta las interrupciones de reloj producidas desde la ultima activación;
lost_ticks_system cuenta, en cambio el numero de interrupciones transcurridas mientras el proceso de
interrupción estaba en Modo de Sistema.
A mi parecer opino que un comentario más extenso de este apartado se sale excesivamente
del ideal de este apartado, que no es más que una leve introducción al funcionamiento de los algoritmos y
procesos más importantes usados en el kernel. Si alguien quiere más información sobre éste, o algunos de
los apartados incluidos en el punto 3.3,le aconsejo que consulte el libro
[BBD+97], capítulo 3, el único inconveniente es para aquellos que no se desenvuelvan bien con el
inglés, aunque si alguien está interesado es un muy buen libro para conocer el funcionamiento del kernel
con mayor precisión.
2.4 EL SISTEMA DE ARCHIVOS DE LINUX
Actualmente es normal encontrar un PC con su disco duro con distintas particiones, cada
una de ellas con un sistema de ficheros distinta. Esta variedad es debida a que prácticamente cada
sistema operativo tiene su propio sistema de ficheros, alegando que éste es más rápido y seguro que el
resto.
Puede que una de las razones por las que Linux ha tenido tanta popularidad, sea por la
cantidad de sistemas de ficheros distintos que soporta (FAT16 y FAT32 de Windows, NTFS de WinNT, HPFS
de OS/2, ISO 9660 y Joliet, que son los estándares más comunes en CD, etc.). El soporte de esta gran
cantidad de sistema de ficheros es debido a la interfaz unificada que usa el kernel llamada
Virtual File System Switch (VFS) o más sencillamente Virtual File System. Este sistema virtual de ficheros
es el encargado de cada proceso pueda manejar información desde los distintos ficheros sin necesidad de
saber donde se encuentran, o de saber si pertenecen a un tipo de sistema de ficheros u otro.
Toda la información obtenida en este apartado ha sido obtenida a partir del libro
[BBD+97] y de la página web [Rusling98], los
cuales recomiendo para todo aquel que esté interesado en profundizar en este tema. Como nota comentar que,
como ya hemos dicho antes, [BBD+97] está en inglés, y la web
[Rusling98] aunque el original está en inglés, se puede encontrar una traducción
al castellano, aunque en estas fechas (Mayo 2000) se encuentra en fase de desarrollo, por lo que hay secciones
traducidas parcialmente, así como también otras no traducidas.
2.4.1 Conocimientos básicos
La CPU no es el único elemento "inteligente" que existe en la computadora. Cada elemento
hardware que la compone lleva incluido su propio controlador (por ejemplo el ratón y el teclado son
controlados por el chip SuperIO, el disco IDE por el controlador IDE o el SCSI por la controladora SCSI).
Esto implica que el acceso a cada uno de estos dispositivos se realizará de forma distinta, por lo que
cada utilidad debería incluir unos controladores. En vez de eso, los controladores se incluyen en el
kernel como unas librerías conocidas como device drivers (controlador de dispositivo), de tal forma que
se puede acceder a todos los dispositivos así configurados, sin necesidad de conocer cómo funciona el
dispositivo a bajo nivel. De esta forma se consigue una abstracción en lo que se refiere al acceso a
dispositivos.
En Linux, como en Unix, a los distintos sistemas de ficheros que el sistema puede usar no
se accede por identificadores de dispositivo (como un número o nombre de unidad) pero, en cambio se
combinan en una estructura jerárquica de árbol que representa el sistema de ficheros como una
entidad única y sencilla. Linux ańade cada sistema de ficheros nuevo en este árbol de sistemas de
ficheros cuando se monta. Todos los sistemas de ficheros, de cualquier tipo, se montan sobre un directorio
y los ficheros del sistema de ficheros son el contenido de ese directorio. Este directorio se conoce como
directorio de montaje o punto de montaje. Cuando el sistema de ficheros se desmonta, los ficheros propios
del directorio de montaje son visibles de nuevo.
Además, gracias a esta forma de trabajo, no es necesario implementar el código necesario
para acceder a los distintos dispositivos, sino que cada proceso se comunica con los dispositivos que
necesite a través del acceso que le es proporcionado a través del VFS, como se puede observar en la
figura siguiente.
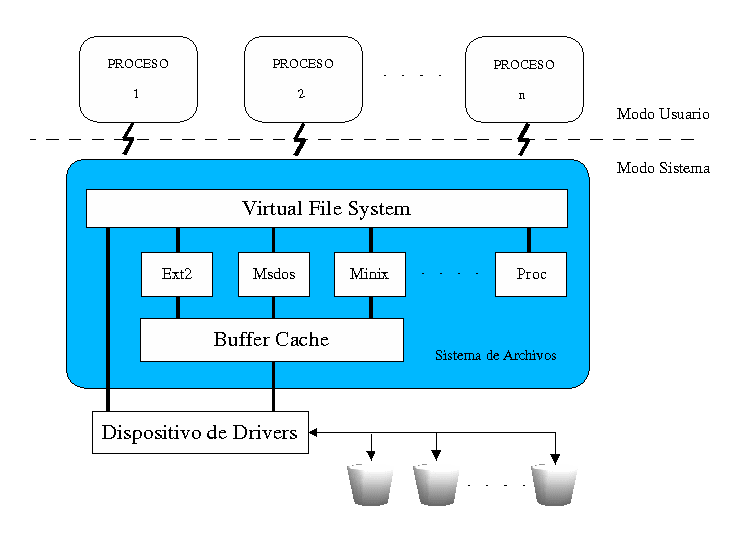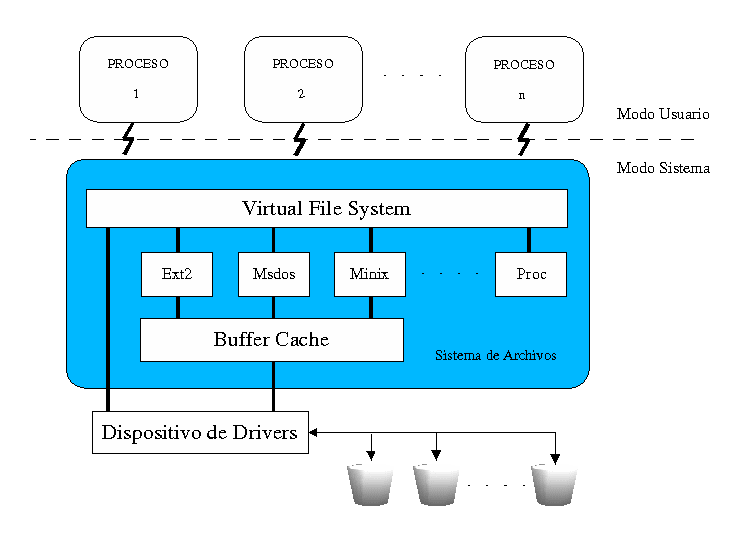
Figura 4 - Estructura del VFS
El primer sistema de ficheros diseńado específicamente para Linux, el sistema de Ficheros
Extendido, o EXT, fue introducido en Abril de 1992 y solventó muchos problemas pero era aún falto de
rapidez. Así, en 1993, el Segundo sistema de Ficheros Extendido, o EXT2, fue ańadido al kernel
como sistema principal de ficheros.
En ese momento un importante desarrollo tuvo lugar en Linux.
El sistema de ficheros real se separó del sistema operativo y servicios del sistema a favor de un interfaz
conocido como el Sistema de Ficheros Virtual, o VFS. VFS permite a Linux soportar muchos, incluso muy
diferentes, sistemas de ficheros, cada uno presentando un interfaz software común a través del VFS. Todos los
detalles del sistema de ficheros de Linux son traducidos mediante software de forma que todo el sistema
de ficheros parece idéntico al resto del kernel de Linux y a los programas que se ejecutan en el sistema.
La capa del sistema de Ficheros Virtual de Linux permite al usuario montar de forma transparente
diferentes sistemas de ficheros al mismo tiempo.
El sistema de Ficheros Virtual está implementado de forma que el acceso a los ficheros es
tan rápido y eficiente como sea posible. También debe asegurar que los ficheros y los datos que contiene
son correctos. Estos dos requisitos pueden ser incompatibles entre si. El VFS de Linux mantiene
una antememoria con información de cada sistema de ficheros montado y en uso. Se debe tener mucho cuidado
al actualizar correctamente el sistema de ficheros ya que los datos contenidos en las antememorias se
modifican cuando se crean, escriben y borran ficheros y directorios. Si se pudieran ver las
estructuras de datos del sistema de ficheros dentro del kernel en ejecución, se podría ver los bloques
de datos que se leen y escriben por el sistema de ficheros. Las estructuras de datos, que describen los
ficheros y directorios que son accedidos serian creadas y destruidas y todo el tiempo los controladores
de los dispositivo estarían trabajando, buscando y guardando datos. La antememoria o caché más importantes
es la llamada Buffer Cache, que está integrada entre cada sistema de ficheros y su dispositivo de bloque. Tal y
como se accede a los bloques se ponen en el Buffer Cache y se almacenan en varias colas dependiendo de
sus estados. El Buffer Cache no sólo mantiene buffers de datos, también ayuda a administrar el interfaz
asíncrono con los controladores de dispositivos de bloque.
2.4.2 El Virtual File System
Como en el sistema de ficheros EXT2, cada fichero, directorio y demás se representan en el
VFS por un y sólo un inodo VFS. La información en cada inodo VFS se construye a partir de información del
sistema de ficheros por las rutinas específicas del sistema de ficheros. Los inodos VFS existen sólo en la
memoria del núcleo y se mantienen en el caché de inodos VFS tanto tiempo como sean útiles para el sistema.
Entre otra información, los inodos VFS contienen los siguientes campos:
- device: Este es el identificador de dispositivo del dispositivo que contiene el fichero o lo que este
inodo VFS represente,
- inode number: Este es el número del inodo y es único en este sistema de ficheros. La combinación de
device y inode number es única dentro del Sistema de Ficheros Virtual,
- mode: Como en EXT2 este campo describe qué representa este inodo VFS y los permisos de acceso
(r-lectura, w-escritura, x-ejecución para propietario, grupo y otros usuarios),
- user ids: Los identificadores de propietario,
- times: Los tiempos de creación, modificación y escritura,
- block size: El tamańo de bloque en bytes para este fichero, por ejemplo 1024 bytes,
- inode operations: Un puntero a un bloque de direcciones de rutina. Estas rutinas son específicas del
sistema de ficheros y realizan operaciones para este inodo, por ejemplo, truncar el fichero que
representa este inodo.
- count: El número de componentes del sistema que están usando actualmente este inodo VFS. Un contador
de cero indica que el inodo está libre para ser descartado o rehusado,
- lock: Este campo se usa para bloquear el inodo VFS, por ejemplo, cuando se lee del sistema de
ficheros,
- dirty: Indica si se ha escrito en este inodo, si es así, el sistema de ficheros necesitará
modificarlo,
- file system specific information.
2.4.3 El sistema de ficheros Ext2
El Segundo sistema de ficheros Extendido de Linux ha sido el que mayor éxito ha cosechado,
siendo básico en cualquier distribución de este S.O. Su construcción se basa en que los datos son
guardados en bloques, los cuales son, en principio, del mismo tamańo, aunque pueden variar de un sistema
a otro (ya que esta elección del tamańo se hace al crear el sistema con mke2fs). Cuando se almacena un
fichero, se hace de tal forma que ocupe un número entero de bloques, quedando gran parte de la capacidad
del último bloque usado bastante desperdiciada, a no ser que el fichero de datos ocupe exactamente un
numero de bloques. No todos los bloques del sistema de ficheros contienen datos, algunos deben usarse para
mantener la información que describe la estructura del sistema de ficheros. EXT2 define la topología del
sistema de ficheros describiendo cada fichero del sistema con una estructura de datos inodo. Un inodo
describe que bloques ocupan los datos de un fichero y también los permisos de acceso del fichero, las horas
de modificación del fichero y el tipo del fichero. Cada fichero en el sistema de ficheros EXT2 se describe
por un único inodo y cada inodo tiene un único número que lo identifica. Los inodos del sistema de ficheros
se almacenan juntos en tablas de inodos. Los directorios EXT2 son simplemente ficheros especiales (ellos
mismos descritos por inodos) que contienen punteros a los inodos de sus entradas de directorio.
El sistema de ficheros EXT2 divide las particiones lógicas que ocupa en Grupos de Bloque
(Block Groups). Cada grupo duplica información crítica para la integridad del sistema de ficheros ya sea
valiéndose de ficheros y directorios como de bloques de información y datos. Esta duplicación es necesaria
por si ocurriera un desastre y el sistema de ficheros necesitara recuperarse.
En el sistema de ficheros EXT2, el inodo es el bloque de construcción básico; cada fichero
y directorio del sistema de ficheros es descrito por un y sólo un inodo. Los inodos EXT2 para cada Grupo de
Bloque se almacenan juntos en la tabla de inodos con un mapa de bits que permite al sistema seguir la pista
de inodos reservados y libres. Un inodo EXT2, entre otra información, contiene los siguientes campos:
- mode: Esto mantiene dos partes de información; qué inodo describe y los permisos que tienen los
usuarios. Para EXT2, un inodo puede describir un ficheros, directorio, enlace simbólico, dispositivo de
bloque, dispositivo de carácter o FIFO.
- owner Information: Los identificadores de usuario y grupo de los dueńos de este fichero o directorio.
Esto permite al sistema de ficheros aplicar correctamente el tipo de acceso,
- size: El tamańo en del fichero en bytes,
- timestamps: La hora en la que el inodo fue creado y la última hora en que se modificó,
- datablocks: Punteros a los bloques que contienen los datos que este inodo describe. Los doce primeros
son punteros a los bloques físicos que contienen los datos descritos por este inodo y los tres últimos
punteros contienen más y más niveles de indirección. Por ejemplo, el puntero de doble indirección apunta
a un bloque de punteros que apuntan a bloques de punteros que apuntan a bloques de datos. Esto significa
que ficheros menores o iguales a doce bloques de datos en longitud son más fácilmente accedidos que
ficheros más grandes.
Los inodos EXT2 pueden describir ficheros de dispositivo especiales. No son ficheros reales
pero permiten que los programas puedan usarlos para acceder a los dispositivos. Todos los ficheros de
dispositivo de /dev están ahí para permitir a los programas acceder a los dispositivos de Linux. Por
ejemplo el programa mount toma como argumento el fichero de dispositivo que el usuario desee montar.
El Superbloque contiene una descripción del tamańo y forma base del sistema de ficheros. La
información contenida permite al administrador del sistema de ficheros usar y mantener el sistema de
ficheros. Normalmente sólo se lee el Superbloque del Grupo de Bloque 0 cuando se monta el sistema de
ficheros pero cada Grupo de Bloque contiene una copia duplicada en caso de que se corrompa sistema de
ficheros. Entre otra información contiene:
- Magic Number: Esto permite al software de montaje comprobar que es realmente el Superbloque para un
sistema de ficheros EXT2. Para la versión actual de EXT2 éste es 0xEF53.
- Revision Level: Los niveles de revisión mayor y menor permiten al código de montaje determinar si este
sistema de ficheros soporta o no características que sólo son disponibles para revisiones particulares
del sistema de ficheros. También hay campos de compatibilidad que ayudan al código de montaje determinar
que nuevas características se pueden usar con seguridad en ese sistema de ficheros,
- Mount Count and Maximum Mount Count: Juntos permiten al sistema determinar si el sistema de ficheros
fue comprobado correctamente. El contador de montaje se incrementa cada vez que se monta el sistema de
ficheros y cuando es igual al contador máximo de montaje muestra el mensaje de aviso «maximal mount count
reached, running e2fsck is recommended»,
- Block Group Number: El número del Grupo de Bloque que tiene la copia de este Superbloque,
- Block Size: El tamańo de bloque para este sistema de ficheros en bytes, por ejemplo 1024 bytes,
- Blocks per Group: El número de bloques en un grupo. Como el tamańo de bloque éste se fija cuando se
crea el sistema de ficheros,
- Free Blocks: EL número de bloques libres en el sistema de ficheros,
- Free Inodes: El número de Inodos libres en el sistema de ficheros,
- First Inode: Este es el número de inodo del primer inodo en el sistema de ficheros. El primer inodo en
un sistema de ficheros EXT2 raíz seria la entrada directorio para el directorio '/'.
2.4.4 Sistema de Ficheros Proc
El sistema de ficheros /proc muestra realmente la potencia del Sistema Virtual de Ficheros.
Este sistema no existe en realidad. Éste como el resto de sistemas de ficheros, se registra en el VFS.
Sin embargo, cuando el VFS hace llamadas al /proc, éste crea los ficheros que le son pedidos con
información sobre el kernel. Por ejemplo la llamada al fichero /proc/devices genera a partir de las
estructuras del kernel, un archivo describiendo sus dispositivos.
El sistema de ficheros /proc representa una ventana hacia el interior del kernel.